{ }
AI
⚡
AUTO
🤖
Sztuczna Inteligencja
Gemini 3.1 Flash Live: Google Właśnie Zabił Tradycyjne Call Center — Darmowy Model Głosowy AI w Czasie Rzeczywistym
30 marca 2026
26 marca 2026 roku Google udostępnił Gemini 3.1 Flash Live — model AI do konwersacji głosowych w czasie rzeczywistym, który przetwarza audio natywnie (bez transkrypcji), rozumie ton głosu, filtruje szum, obsługuje 90+ języków i jest dostępny za darmo w API. Search Live powered by Flash Live działa już w 200+ krajach.

Gemini 3.1 Flash Live: Google Właśnie Zabił Tradycyjne Call Center — Darmowy Model Głosowy AI w Czasie Rzeczywistym
26 marca 2026 roku Google udostępnił Gemini 3.1 Flash Live — model AI do konwersacji głosowych w czasie rzeczywistym, który eliminuje całą tradycyjną architekturę voice AI. Zamiast łańcucha STT → LLM → TTS, Flash Live przetwarza audio natywnie — rozumie ton, tempo, pitch, filtruje szum otoczenia i odpowiada z minimalnym opóźnieniem. 90+ języków. Function calling głosem. I na razie — za darmo w API.
To nie jest “kolejny chatbot z głosem”. Flash Live to zmiana architektury — model, który słyszy, nie tylko czyta. I Google już go wdrożył: Search Live z Flash Live działa w 200+ krajach.
Dlaczego Flash Live to przełom, a nie iteracja
Dotychczasowe systemy voice AI działały jak fabryka z czterema oddzielnymi halami: mikrofon → transkrypcja mowy na tekst (STT) → model językowy generuje odpowiedź → synteza tekstu na mowę (TTS) → głośnik. Każdy krok to opóźnienie. Każdy krok to utrata informacji — bo transkrypcja nie przenosi tonu, sarkazmu, wahania, emocji.
Gemini 3.1 Flash Live łączy to w jeden pipeline: natywne przetwarzanie audio end-to-end. Model przyjmuje surowe PCM 16-bit/16kHz na wejściu i zwraca PCM 24kHz na wyjściu. Żadnej transkrypcji pośredniej. To znaczy, że model dosłownie “słyszy” — rozpoznaje niuanse akustyczne, pitch, tempo mówienia i odróżnia mowę od szumów otoczenia (ruch uliczny, telewizor, rozmowy w tle).
W testach z szumem drogowym i gwarnym otoczeniem Flash Live odfiltrowywał mowę od zakłóceń z dokładnością, której poprzedni model (2.5 Flash Native Audio) nie osiągał.
Co potrafi Gemini 3.1 Flash Live — pełna lista zdolności
Real-time audio + video + tekst jednocześnie
Flash Live to model multimodalny: przyjmuje tekst, obrazy, audio i wideo na wejściu, a na wyjściu generuje audio i tekst. Wideo streamowane jest jako klatki JPEG/PNG ~1 FPS. Oznacza to, że możesz zbudować agenta, który jednocześnie słucha użytkownika, widzi jego kamerę i odpowiada głosem — w czasie rzeczywistym.
90+ języków
Model jest natywnie wielojęzyczny. To nie jest “tłumaczenie w tle” — Flash Live generuje odpowiedzi w danym języku od podstaw. To właśnie umożliwiło globalną ekspansję Search Live do 200+ krajów.
Function calling głosem (ComplexFuncBench Audio: 90.8%)
To najciekawsza zdolność dla developerów: Flash Live obsługuje function calling bezpośrednio z audio — bez pośredniej transkrypcji na tekst. Na benchmarku ComplexFuncBench Audio, który mierzy wielokrokowe wywoływanie funkcji z różnymi ograniczeniami, Flash Live osiąga 90.8%.
Co to oznacza praktycznie? Możesz powiedzieć: “Sprawdź status mojego zamówienia numer 4827, a jeśli jest opóźnione, złóż reklamację i wyślij mi mail z potwierdzeniem” — i model wykona to jako sekwencję function calls, bez utraty kontekstu.
Barge-in — przerywanie modelu w trakcie odpowiedzi
Flash Live obsługuje tzw. “inteligentny barge-in” — wykraczający poza prostą detekcję aktywności głosowej (VAD). Model sam decyduje, kiedy powinien odpowiedzieć, a kiedy być “cichym współsłuchaczem”. Możesz przerwać mu w pół zdania i zmienić temat — zareaguje natychmiast.
2x dłuższy kontekst konwersacji
W porównaniu z poprzednikiem, Flash Live utrzymuje wątek rozmowy dwa razy dłużej. Dłuższe burze mózgów, wielowątkowe konsultacje, złożone sesje customer service — model nie gubi kontekstu.
Watermarking audio (anty-deepfake)
Wszystkie wygenerowane audio są automatycznie oznaczane watermarkiem. To odpowiedź Google na rosnące zagrożenie deepfake’ami głosowymi i dezinformacją.
Specyfikacja techniczna
| Parametr | Wartość |
|---|---|
| Model ID | gemini-3.1-flash-live-preview |
| Input | Tekst, audio (PCM 16-bit, 16kHz), obrazy, wideo (~1 FPS JPEG/PNG) |
| Output | Audio (PCM 24kHz), tekst |
| Context window | Do 128K tokenów |
| Max output | 64K tokenów |
| Języki | 90+ |
| Benchmark | ComplexFuncBench Audio: 90.8% |
| Połączenie | WebSocket (bi-directional streaming) |
| Session limits | Audio: 15 min, Audio+Video: 2 min (z resumption: nieograniczone) |
| Resumption tokens | Ważne 2h po zakończeniu sesji |
| Cena API (preview) | Za darmo (marzec 2026) |
| Audio tokenizacja | ~25 tokenów/sekundę audio |
| Watermarking | Automatyczne na wyjściu audio |
| Function calling | Tak (sekwencyjne, deklarowane przy starcie sesji) |
Jak działa pod maską — WebSocket i session management
Flash Live działa przez persystentne połączenie WebSocket — nie klasyczne REST API. Klient łączy się z endpointem wss://generativelanguage.googleapis.com/ws/..., wysyła konfigurację sesji (model, parametry, system instructions, narzędzia) i utrzymuje dwukierunkowy strumień.
Session Resumption — nieograniczone sesje
Standardowo sesje audio trwają max 15 minut (audio+video: 2 minuty). Ale Google dodał mechanizm session resumption: serwer wysyła tokeny wznowienia, które pozwalają kontynuować sesję po resecie WebSocket. Tokeny ważne 2h. W połączeniu z kompresją okna kontekstowego — sesje mogą trwać teoretycznie nieograniczenie.
Function calling w sesji
Wszystkie funkcje muszą być zadeklarowane na starcie sesji (w BidiGenerateContentSetup). Model może generować wiele function calls z jednego promptu i łączyć ich wyniki w łańcuch — kod wykonuje się w sandboxie, a model czeka na wynik każdej funkcji przed kolejnym krokiem.
Ważne ograniczenie: aktualnie Flash Live obsługuje tylko sekwencyjne tool calling (nie równoległe).
Gdzie Google już wdrożył Flash Live
Search Live — 200+ krajów
Największe wdrożenie: Search Live napędzany Gemini 3.1 Flash Live jest teraz dostępny w 200+ krajach i terytoriach. Wcześniej limitowany do USA, teraz globalny. Użytkownicy mogą:
- Mówić do wyszukiwarki zamiast pisać
- Zadawać pytania follow-up w konwersacji
- Kierować kamerę na obiekty (przez Google Lens) i pytać o nie głosem
- Otrzymywać odpowiedzi audio z linkami do źródeł
Dostęp: Google App na Android/iOS → ikona Live pod paskiem wyszukiwania.
Gemini Live — asystent głosowy
Gemini Live (asystent w ekosystemie Google) również przeszedł na Flash Live. Szybsze odpowiedzi, dłuższe konteksty, lepsze rozumienie tonu. Dostępny w 200+ krajach.
5 zastosowań, które zmienią reguły gry
1. Customer service na sterydach
Flash Live + function calling = bot telefoniczny, który:
- Sprawdza status zamówienia
- Przetwarza zwroty i reklamacje
- Rezerwuje terminy
- Rozumie ton klienta (frustracja, pilność)
- Obsługuje 90+ języków bez osobnych modeli
Jeden model zamiast call center z 50 agentami. Koszty? Na razie API za darmo w preview.
2. Asystent spotkań w real-time
Agent, który dołącza do spotkania, transkrybuje, odpowiada na pytania uczestników i trigger’uje akcje follow-up w trakcie rozmowy. Nie “po spotkaniu” — w trakcie.
3. Wielojęzyczny kompanion dla seniorów
Jeden z realnych case’ów podawanych przez Google: AI companion dla osób starszych, który prowadzi konwersację w ich ojczystym języku, przypomina o lekach i łączy z pomocą w razie potrzeby.
4. Voice-controlled design tools
Projektant mówi “przesuń ten element w prawo, zmniejsz font do 14, zmień kolor na niebieski” — a narzędzie wykonuje komendy w real-time. Flash Live + function calling to infrastruktura do takich integracji.
5. RPG Game Master z teatralną narracją
Tak, Google wprost wymienia to jako use case: AI mistrz gry RPG, który prowadzi sesję głosem z emocjami, reaguje na decyzje graczy i zarządza mechanikami gry przez function calling.
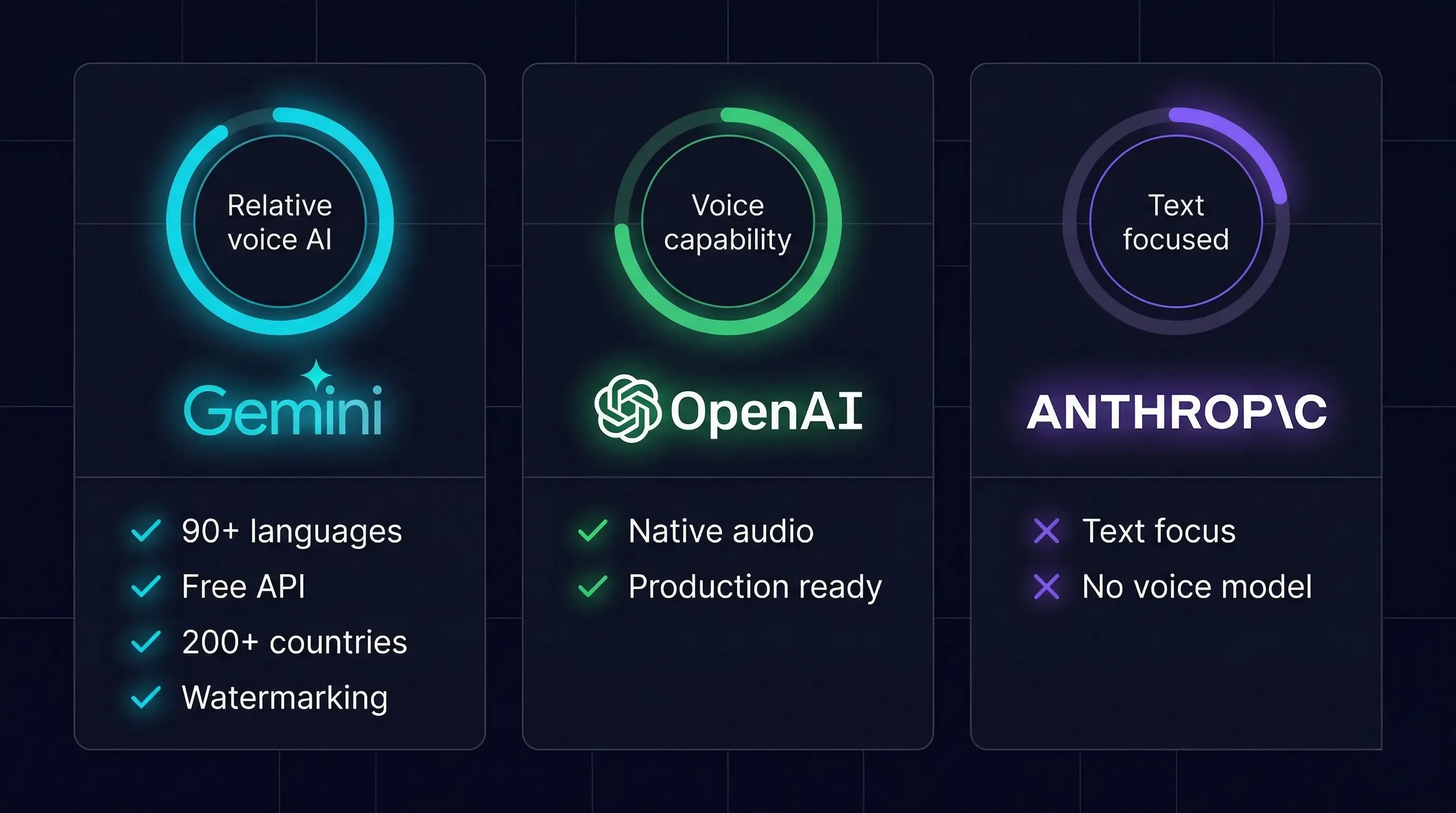
Flash Live vs konkurencja — porównanie modeli głosowych AI
| Cecha | Gemini 3.1 Flash Live | GPT-4o Realtime (OpenAI) | Claude (Anthropic) |
|---|---|---|---|
| Natywne audio | Tak (end-to-end) | Tak (od GPT-4o) | Brak dedykowanego modelu głosowego |
| Języki | 90+ | ~50 | N/A |
| Function calling głosem | Tak (90.8% ComplexFuncBench) | Tak | N/A |
| Wideo real-time | Tak (~1 FPS) | Ograniczone | N/A |
| Barge-in | Inteligentny (kontekstowy) | Podstawowy (VAD) | N/A |
| Cena API | Za darmo (preview) | Płatne | N/A |
| Session resumption | Tak (tokeny 2h) | Ograniczone | N/A |
| Watermarking | Automatyczne | Brak | N/A |
| Globalny zasięg | 200+ krajów (Search Live) | Ograniczony | N/A |
Google ma tu wyraźną przewagę: 90+ języków, darmowe API w preview, globalne wdrożenie i pełna multimodalność (audio + video + tekst + narzędzia). OpenAI ma GPT-4o z natywnym audio, ale ograniczony zasięg językowy i brak darmowego dostępu. Anthropic z Claude skupia się na tekście i kodowaniu — Claude Mythos to tier premium do cybersec i reasoning, nie voice.
Co to oznacza dla automatyzacji i biznesu
Voice-first automation staje się realna
Do tej pory automatyzacja głosowa wymagała sklejania 4+ usług: Twilio + Whisper + GPT + ElevenLabs. Flash Live to jeden endpoint. Dla firm budujących pipeline’y z n8n lub Make, to oznacza: jeden webhook do API Google zamiast 4 osobnych integracji.
Bariery językowe znikają
90+ języków w jednym modelu = globalny customer service bez osobnych modeli na każdy rynek. Firma z Polski obsługuje klientów z Niemiec, Francji, Japonii — tym samym agentem. To jest game changer dla e-commerce, szczególnie dla firm pracujących z Base (BaseLinker) na wielu marketplace’ach jednocześnie.
Darmowe API = czas na eksperymenty
Preview jest za darmo. To okno na budowanie MVP, testowanie use case’ów i walidację pomysłów bez kosztów API. Docelowa cena (po wyjściu z preview) prawdopodobnie będzie bazować na tokenach (~25 tokenów/sekundę audio). Dla porównania: Gemini 3 Flash (tekst) kosztuje $0.50/$3.00 za 1M tokenów — Flash Live będzie droższy, ale wciąż w kategorii “tani”.
Partnerzy integracyjni
Google ogłosił partnerstwa z: LiveKit, Pipecat (Daily), Fishjam (Software Mansion), Vision Agents (Stream) i Voximplant — to infrastruktura do budowania produkcyjnych voice agents.
Ograniczenia — o czym Google nie krzyczał
Warto znać limity przed budowaniem na Flash Live:
- Sequential tool calling only — brak równoległych function calls. Każde narzędzie musi zakończyć pracę, zanim model wywoła następne
- Session limits — 15 min audio, 2 min video (z resumption nieograniczone, ale wymaga implementacji)
- Preview = nie do produkcji — Google wprost pisze, że preview nie jest przeznaczony do zastosowań produkcyjnych. Warunki i ceny mogą się zmienić
- WebSocket complexity — to nie REST API. Session management, PCM streaming, obsługa przerywań, ephemeral tokens — znacząco większa złożoność niż standardowe API
- ~1 FPS wideo — to nie jest videostreaming. Jedna klatka na sekundę wystarcza do analizy sceny, ale nie do śledzenia szybkiego ruchu
Jak zacząć — quickstart dla developerów
Minimalna ścieżka do pierwszego voice agenta:
- Google AI Studio → otwórz projekt, wybierz model
gemini-3.1-flash-live-preview - WebSocket → połącz z
wss://generativelanguage.googleapis.com/ws/... - Konfiguracja sesji → wyślij
BidiGenerateContentSetupz modelem, system instructions i narzędziami - Streamuj audio → 16-bit PCM, 16kHz, little-endian
- Odbieraj odpowiedzi → PCM 24kHz na wyjściu
Przykłady kodu i oficjalne demo: github.com/google-gemini/gemini-live-api-examples
Dla firm, które nie chcą budować od zera: agenci AI i automatyzacja z LinkWith.it — pomożemy zintegrować Flash Live z Twoim stackiem.
FAQ
Czym jest Gemini 3.1 Flash Live?
Gemini 3.1 Flash Live to model AI od Google do konwersacji głosowych w czasie rzeczywistym, udostępniony 26 marca 2026. Przetwarza audio natywnie (bez transkrypcji), obsługuje 90+ języków, function calling głosem (ComplexFuncBench Audio 90.8%) i streaming audio + video jednocześnie.
Czy Gemini 3.1 Flash Live jest za darmo?
Tak, w marcu 2026 model jest dostępny za darmo w Gemini API jako preview (gemini-3.1-flash-live-preview). Google zastrzega, że preview nie jest przeznaczony do produkcji i warunki mogą się zmienić. Docelowa cena bazować będzie na tokenach (~25 tokenów/sekundę audio).
Czym Flash Live różni się od zwykłego Gemini?
Standardowe modele Gemini (Flash, Pro) to modele tekstowe — przyjmują tekst/obraz i zwracają tekst. Flash Live to model audio-native: przyjmuje surowe audio PCM i zwraca audio. Działa przez WebSocket (nie REST), obsługuje barge-in (przerywanie) i session resumption. To zupełnie inna architektura — dla voice-first aplikacji.
Jakie są ograniczenia Flash Live?
Główne ograniczenia: sesje audio max 15 min bez resumption (z resumption nieograniczone), video max 2 min, sequential tool calling (brak równoległego), preview = nie do produkcji, WebSocket wymaga więcej implementacji niż REST API, video ~1 FPS.
Czy mogę zbudować voice bota customer service na Flash Live?
Tak, to jeden z głównych use case’ów. Flash Live z function calling pozwala zbudować bota, który sprawdza zamówienia, przetwarza zwroty, rezerwuje terminy i rozumie ton klienta — w 90+ językach. Ale w marcu 2026 model jest w preview — do produkcji warto poczekać na stabilną wersję lub budować MVP z myślą o migracji.
Jak Gemini 3.1 Flash Live wypada na tle GPT-4o Realtime?
Flash Live ma przewagę w: liczbie języków (90+ vs ~50), cenie (za darmo vs płatne), globalnym zasięgu (Search Live w 200+ krajach), watermarkingu audio i inteligentnym barge-in. GPT-4o Realtime jest bardziej dojrzałe produkcyjnie. Oba modele przetwarzają audio natywnie.
Wnioski
Gemini 3.1 Flash Live to nie upgrade — to zmiana paradygmatu. Google zlikwidował 3 z 4 kroków tradycyjnej architektury voice AI, zbudował model natywnie multimodalny i dał go developerom za darmo w preview.
90+ języków, function calling głosem, session resumption, inteligentny barge-in — to infrastruktura do budowania voice agents, które do tej pory wymagały zespołu inżynierów i 4 osobnych usług.
Dla firm: okno na darmowe eksperymenty jest otwarte. Dla call center: zegar tyka.
Chcesz zacząć przygodę z automatyzacją na poważnie?
- Skorzystaj z naszej rekomendacji hostingu pod n8n: Hostinger -20% z kodem linkwithit – to najtańsza opcja na własny, niezależny system.
- Potrzebujesz pomocy we wdrożeniu voice AI w swojej firmie? Sprawdź nasze usługi. Pomożemy Ci zbudować agentów, którzy pracują, gdy Ty śpisz.
Gotowy na transformację?
Umów bezpłatną konsultację lub zapisz się do newslettera.